Method
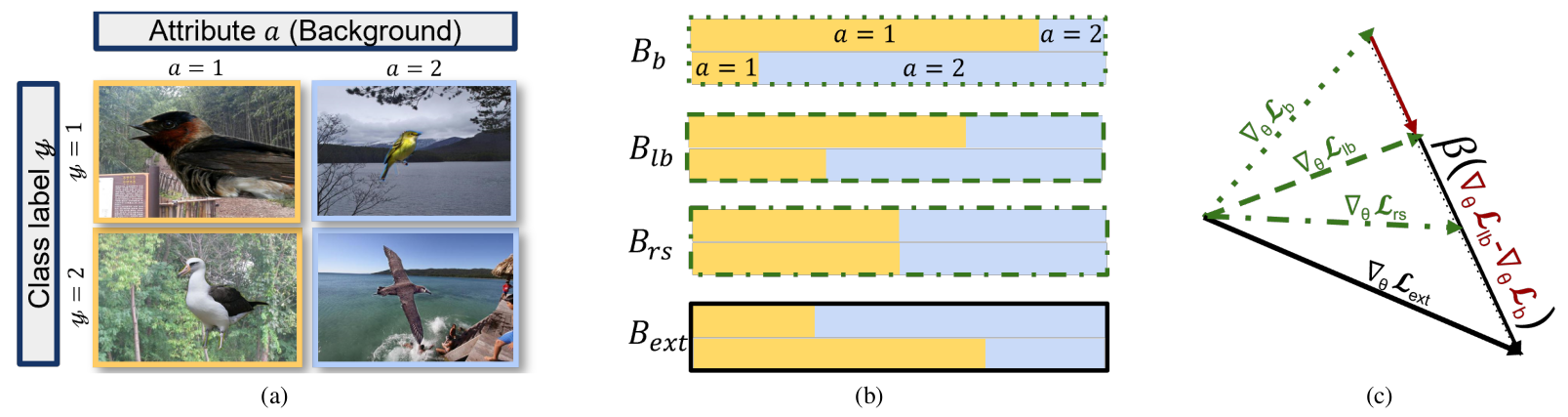
(a) Sample images from the Waterbirds classification task. Most landbird images appear with land backgrounds (i.e., y=1, a=1), while most waterbird images appear with water backgrounds (i.e., y=2, a=2). This correlation between bird class and background introduces spurious correlations in the dataset.
(b) Visualization of batch construction. Bb shows a biased batch where the majority of images from class y=1 (top row) have attribute a=1 (yellow), and most images from class y=2 (bottom row) have attribute a=2 (light-blue). Blb represents a less biased batch, with a more balanced attribute distribution within each class, controlled by c (here c=1/2). Brs depicts a group-balanced distribution and refers to a batch sampled using the Resampling method. Bext simulates GERNE's batch with c · (β + 1) > 1, where the dataset’s minority group appears as the majority in the batch.
(c) A simplified 2D representation of gradient extrapolation where θ ∈ ℝ². ∇θℒb is the gradient computed on Bb; training with this gradient is equivalent to training with the ERM objective. ∇θℒlb is computed on Blb. ∇θℒrs is the gradient computed on Brs, which is equivalent to an extrapolated gradient with c · (β + 1) = 1. Finally, ∇θℒext is our extrapolated gradient, with the extrapolation factor β modulating the degree of debiasing in conjunction with the strength of spurious correlations in the dataset.
Ablation Study
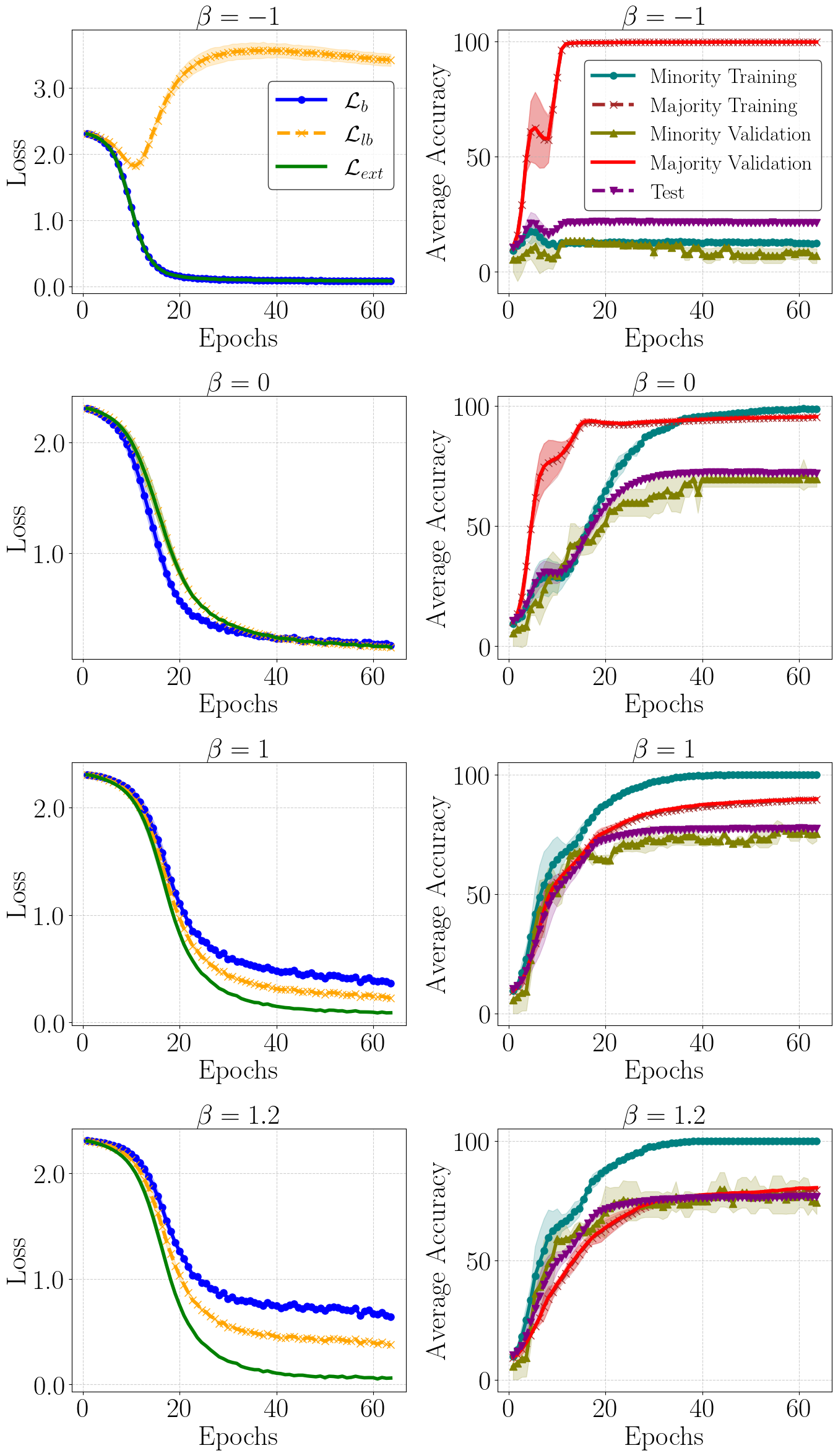
The impact of tuning β in debiasing the model (β ∈ {−1, 0, 1, 1.2}) is shown. On the left column, we plot the training losses ℒb, ℒlb, and the target loss ℒext. On the right column, we plot the average accuracy of the minority and majority groups in both training and validation, as well as the average accuracy of the unbiased test set. Each plot represents the mean and standard deviation calculated over three runs with different random seeds.
Acknowledgments
This work was funded by the Carl Zeiss Foundation within the project Sensorized Surgery, Germany (P2022-06-004). Maha Shadaydeh is supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)-Individual Research Grant SH 1682/1-1.
We thank Tim Büchner, Niklas Penzel, and Jan Blunk for their manuscript feedback and advice throughout the project.
BibTeX (arXiv Preprint)
@misc{asaad2025gradientextrapolationdebiasedrepresentation,
title={Gradient Extrapolation for Debiased Representation Learning},
author={Ihab Asaad and Maha Shadaydeh and Joachim Denzler},
year={2025},
eprint={2503.13236},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2503.13236},
}